Développement piloté par les spécifications de l’IA : pourquoi la structure est plus importante que jamais
L’IA a discrètement changé notre façon de construire des logiciels. Pas dans le sens « robots remplaçant les ingénieurs ». Pas dans le sens dramatique, réécrit du jour au lendemain de son architecture, mais de manière plus subtile — et plus importante.
Le code est devenu bon marché.
On peut décrire une fonctionnalité et obtenir un brouillon fonctionnel en quelques secondes. Contrôleurs, services, modèles de bases de données, tests — tout cela généré avant même que vous ayez fini votre café. Et cela change la donne, car si le code n’est plus le goulot d’étranglement, alors qu’est-ce qui l’est ?
Clarté.
Le vrai problème n’est pas le code. C’est de l’ambiguïté.
L’IA est très douée pour combler les lacunes. Le problème, c’est qu’elle ne sait pas quels espaces sont intentionnels et lesquels sont dangereux.
Si vous dites :
« Créer une fonction de réinitialisation sécurisée du mot de passe. »
Vous aurez quelque chose qui a l’air correct.
Mais est-ce que ça a été le cas :
Faire respecter l’expiration des jetons ?
Empêcher la réutilisation des jetons ?
Ajouter une limitation de taux ?
Les jetons de réinitialisation de hachage correctement ?
Faire respecter des règles de mot de passe strictes ?
Définir des transitions d’état claires ?
Peut-être, peut-être pas.
Et voici la vérité inconfortable : le résultat sera confiant dans tous les cas. C’est là que le développement piloté par les spécifications devient crucial — surtout dans les flux de travail assistés par l’IA.
Un petit mot sur le développement guidé par les spécifications
Le développement piloté par les spécifications n’est pas nouveau, au fond, il signifie simplement : définir clairement et structurellement le comportement du système avant (et parallèlement) à l’implémentation.
Pas des descriptions vagues.
Pas des exigences dispersées.
Pas des suppositions enfouies dans les réunions.
Définitions structurées :
Contrats API
Règles de validation des données
Transitions de flux de travail
Contraintes de sécurité
Schémas de bases de données
Par le passé, cela aidait les équipes à rester alignées, avec l’IA dans le lot, cela fait quelque chose d’encore plus important : cela limite la génération.
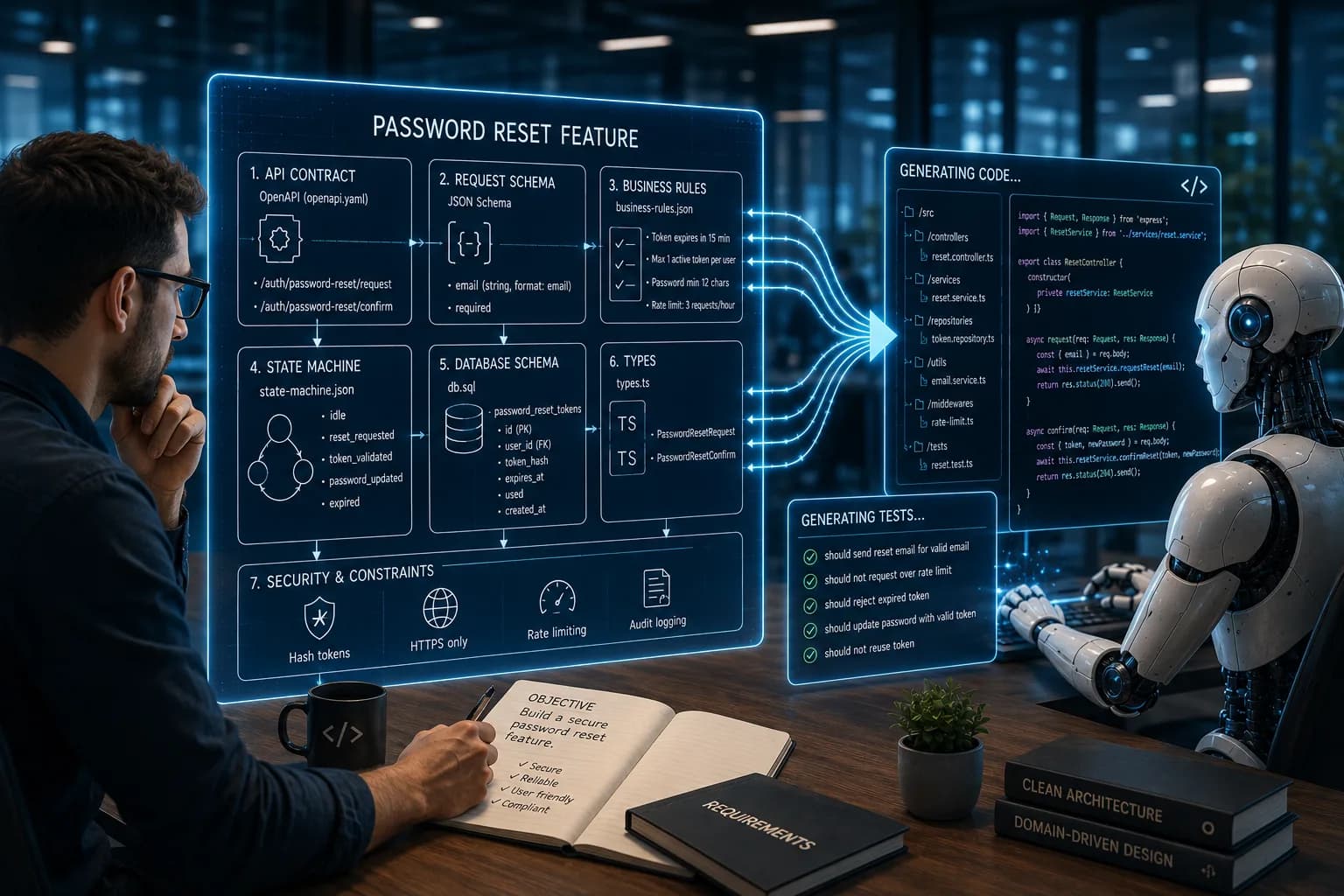
Réalisons ça : une fonction de réinitialisation de mot de passe
Imaginez que nous implémentons la réinitialisation du mot de passe dans un système de production, selon une approche traditionnelle, vous écririez des tickets, discuteriez des cas particuliers, et quelqu’un l’implémenterait.
Dans un flux de travail axé sur l’IA d’abord, vous pouvez plutôt organiser la fonctionnalité ainsi :
/features/password-reset
openapi.yaml
request.schema.json
business-rules.json
state-machine.json
db.sql
implementation/
Remarquez ce qui se passe ici, la fonctionnalité n’est pas seulement du code, c’est un ensemble de définitions structurées, le code devient la dernière étape — pas la première.
Le contrat API
En utilisant la spécification OpenAPI, vous définissez :
/auth/password-reset/request/auth/password-reset/confirmOrganismes demandeurs obligatoires
Réponses attendues
Codes d’état HTTP
Aujourd’hui, l’IA ne peut plus inventer des points d’extrémité ni changer la forme des charges utiles sans violer le contrat.
La couche de validation
Un schéma JSON définit :
Le format de l’email doit être valide
Domaines obligatoires
Types explicites
Cela empêche l’IA d’ajouter des champs supplémentaires de façon « utile » ou de sauter la logique de validation.
Les règles métier
Au lieu d’enterrer les contraintes dans les commentaires, vous les définissez explicitement :
Le jeton expire dans 15 minutes
Un seul jeton actif par utilisateur
Le mot de passe doit être de 12+ caractères
Doit inclure des majuscules, un numéro, un caractère spécial
Maximum 3 tentatives de réinitialisation par heure
L’IA ne devine pas ce que signifie « sécurisé », elle applique des contraintes déclarées.
La machine à l’État
Définissez les états autorisés :
Ralenti
reset_requested
token_validated
password_updated
expiré
Et les transitions juridiques entre eux. Soudain, il devient impossible (par conception) pour l’IA de permettre une mise à jour de mot de passe sans validation de jeton, la structure supprime des classes entières de bugs.
La couche de base de données
Même au niveau du stockage, vous définissez :
Hachages de jetons (pas jetons bruts)
Horodatages d’expiration
Index pour la recherche
Contraintes pour empêcher la réutilisation
Même si la logique applicative échoue, que la base de données impose des invariants, c’est à cela que ressemble une spécification en couches.
Pourquoi cela est important à l’ère de l’IA
L’IA ne fait généralement pas un échec bruyant, elle échoue subtilement, elle peut :
Limitation du taux de saut
Oubliez un cas limite
Implémenter partiellement les règles de mot de passe
Oublier d’invalider les jetons
Supposons des défauts de paiement non sécurisés
Aucune de ces erreurs ne constitue une erreur dramatique, mais à grande échelle, elles s’accumulent ; Le vrai danger n’est pas un mauvais code, c’est un code plausible que personne ne remet en question. L’IA accélère l’exécution, les Specs protègent l’intention.
Le problème des hallucinations
Parlons du mot que personne n’aime : hallucination. Les modèles d’IA comblent parfois les éléments manquants par des hypothèses raisonnables. Dans un contexte créatif, cela me va, mais dans un flux de travail sensible à la sécurité, c’est dangereux.
Si vous ne précisez pas explicitement :
Limites de taux
Politiques de sécurité
Comportement d’expiration
Exigences de journalisation
L’IA peut les omettre, pas de façon malveillante, simplement parce qu’ils n’ont pas été mentionnés, et l’ambiguïté au moment de la génération devient une vulnérabilité à l’exécution.
Ce qui change lorsque vous adoptez un développement basé sur les spécifications de l’IA
Vous arrêtez de vérifier l’implémentation pour l’intention et vous commencez à la revoir pour l’alignement.
Au lieu de demander :
« Ça te semble correct ? »
Vous demandez :
« Est-ce que ça correspond à la spécification ? »
Ce changement réduit considérablement la charge cognitive et rend aussi la régénération plus sûre. Si les exigences changent, vous mettez à jour la spécification — et vous régénérez, car la spécification est structurée, le système évolue de manière prévisible.
Le plus grand avantage
Cette approche fait plus que réduire les hallucinations.
Cela s’améliore :
Alignement entre équipes
Posture de sécurité
Traçabilité de la conformité
Sécurité de régression
Confiance en régénération
Maintenabilité à long terme
Et peut-être le plus important : cela force à la clarté dès le début.
L’IA ne supprime pas le besoin de pensée architecturale, elle amplifie toute réflexion que vous y apportez. Si vos entrées sont vagues, l’IA évolue dans le flou, si vos spécifications sont structurées, l’IA évolue la précision.
L’IA a rendu l’écriture de code plus facile que jamais, mais elle n’a pas facilité la définition des systèmes, au contraire, elle a rendu la clarté plus précieuse. Le développement piloté par les spécifications à l’ère de l’IA ne se résume pas à la documentation.
Il s’agit de créer des limites structurées pour que la rapidité ne compromette pas la justesse. Car lorsque la génération est instantanée et que le code est bon marché, l’ambiguïté devient le bug le plus coûteux de votre système.
Articles Similaires

Les risques cachés de sécurité des outils d’IA sur le lieu de travail
Les outils d’IA transforment le lieu de travail — mais ils introduisent des risques de sécurité cachés, allant de la fuite de données et de l’IA parallèle aux vulnérabilités de conformité et d’intégration.
Lire la Suite →
Pourquoi vous ne pouveza plus vous inscrire à GitHub Copilot Pro (et ce qui change le 1er juin)
Les inscriptions à GitHub Copilot Pro et Pro+ ne sont plus disponibles pour les nouveaux utilisateurs. Découvrez pourquoi GitHub a suspendu les abonnements et comment le passage à la tarification à l'usage prévu le 1er juin va changer Copilot pour les développeurs.
Lire la Suite →